Poiché il software trasforma i dati in ingresso, ogni applicazione potrebbe essere considerata una macchina – “virtuale” ovviamente, data l’assenza di parti fisiche. Un compilatore, ad esempio, prende in input il codice sorgente e lo trasforma in codice binario per poter essere eseguito. Ma anche un semplice editor di immagini prende in input e produce pixel, applicando delle operazioni per ogni pixel o gruppi di pixel: i cosiddetti filtri ed effetti.
Quindi nonostante la sua caratteristica virtuale, il software si comporta come qualsiasi altra macchina: necessita dell’inserimento di materie prime, come ad esempio un elenco di numeri, dei dati incapsulati in XML o un comando di un protocollo. Ma se un programma viene “alimentato” con il materiale sbagliato – un tipo o una forma diversa da quello richiesto – il risultato rischia di essere imprevedibile se non catastrofico. Provate a mettere dei sassolini all’interno di un frullatore e mi fate sapere… Un famoso detto in campo informatico dice: “Garbage in, garbage out“.
Tutti i problemi non banali richiedono un controllo sui dati di input, un “filtro” che impedisca l’inserimento di dati errati e prevenire così un output di conseguenza errato. Questo è certamente il caso delle applicazioni web sviluppate in PHP. Se l’input proviene da un form o da una richiesta Ajax, il programma dovrebbe controllare i dati di input prima di eseguire qualsiasi tipo di calcolo. Potrebbe darsi il caso che un valore numerico debba essere scelto nei limiti di un range di numeri, oppure che debba essere un numero positivo o di una certa lunghezza. Potrebbe verificarsi il caso di dover inserire un formato specifico, come un codice di avviamento postale. In italia i CAP sono di 5 cifre, oppure una partita IVA, a 11 cifre. Oppure ancora una data di nascita nel formato italiano gg/mm/aaaa. Insomma, un’applicazione PHP deve essere sviluppata in modo robusto tenendo conto di questi fattori e di tutti i potenziali pericoli esterni che potrebbero alterare il comportamento dell’applicazione o eludere la sicurezza.
Ma come fa un programma a capire se un dato in input è conforme, ad esempio, a un codice postale? Fondamentalmente, è necessario implementare un piccolo parser per effettuare il match dei dati: a tutti gli effetti un automa a stati finiti in grado di leggere l’input, processare i dati, monitorare lo stato e restituire un risultato. Ma creare un semplice parser potrebbe in realtà essere molto complicato.
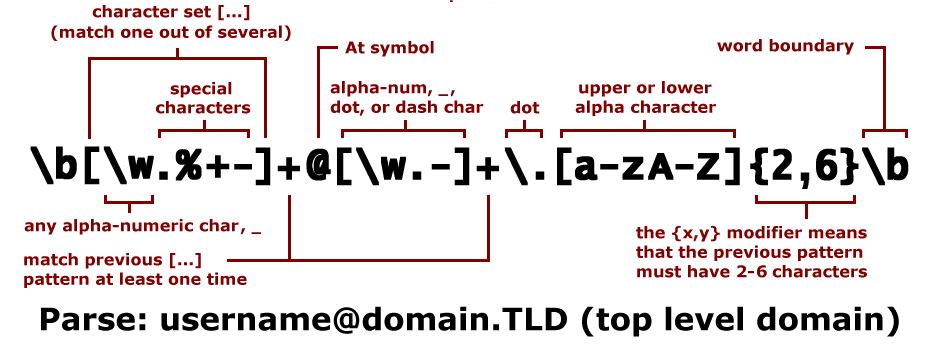
Per fortuna, le operazioni di “pattern-matching” in informatica sono molto comuni (fin dagli albori di UNIX o giù di lì) e ciò ha consentito lo sviluppo di librerie e funzioni che col tempo si sono evoluti. Un’espressione regolare (regex) descrive un modello (che d’ora in poi chiameremo pattern) che, grazie a una particolare notazione concisa e leggibile, consente di raggruppare, descrivere, identificare stringhe che presentino una certa regolarità al suo interno.
Un esempio di espressioni regolari lo fornisce il comando grep di Unix (o Linux), che cerca un pattern specifico dentro uno o più file di testo in Unix. Il comando
grep -i -e '^Bat'
ricerca nei contenuti dei file le corrispondenze che hanno un inizio di linea (indicata con l’accento circonflesso ^), seguita immediatamente dalle lettere b, a, e t (l’opzione -i serve per ad ignora il case sensitive, quindi B e b sono equivalenti). Quindi, dato il file eroi.txt:
Catwoman Batman The Tick Black Cat Batgirl Danger Girl Wonder Woman Luke Cage The Punisher Ant Man Dead Girl Aquaman SCUD Blackbolt Martian Manhunter
Il comando grep produrrebbe due corrispondenze:
Batman Batgirl
Molti fanno la prima conoscenza delle espressioni regolari grazie ai file .htaccess in ambiente Linux, ad esempio, per il rewrite url ma questa è solo una minima parte. In qualsiasi altro linguaggio di programmazione, le espressioni regolari sono ampiamente utilizzate. In particolare nel PHP abbiamo due metodi per la definizione di espressioni regolari, uno chiamato Portable Operating System (POSIX) e un altro Perl Compatible Regular Expressions (PCRE). In generale è preferibile utilizzare PCRE, perché è molto più potente di POSIX, in quanto offre tutti gli operatori presenti in Perl, che è il re indiscusso delle espressioni regolari. Nel prossimo articolo vedremo le caratteristiche base dello standard PCRE.


